小伙伴们要照顾好自己哇!但也不要慌张,开开心心过大年
(1)出门戴口罩,勤洗手
(2)咳嗽或打喷嚏时捂住口鼻
(3)将肉蛋彻底做熟
(4)避免与呼吸道患者密切接触
(5)避免近距离接触野生动物或活牲畜
(6)不要随地吐痰
(7)不要去人多的地方凑热闹
(源于人民日报官方微博)

小伙伴们要照顾好自己哇!但也不要慌张,开开心心过大年
(1)出门戴口罩,勤洗手
(2)咳嗽或打喷嚏时捂住口鼻
(3)将肉蛋彻底做熟
(4)避免与呼吸道患者密切接触
(5)避免近距离接触野生动物或活牲畜
(6)不要随地吐痰
(7)不要去人多的地方凑热闹
(源于人民日报官方微博)

onevps成立于2012年的国外VPS商家,属于Think Huge Ltd的子品牌,2020年商家对其VPS方案做出了一些调整:基本套餐每月给到2T流量,也可以按需付费增加,另外新加坡、日本、洛杉矶这三个节点不再需要额外付费就可以使用(以前日本新加坡要多加6美金呢),相比较现在非常具有性价比;这三个地区的网络速度对国内用户来说还是很不错的,很适合有科学上网需求的用户,有需要的赶紧入手啊(ps:兄弟们好好珍惜,这么便宜又好用的节点不多了啊,别把人家网络又玩坏咯)。
官网地址:https://www.onevps.com/
2020最新优惠码:

Vultr的2020年最新优惠活动来了,如果你之前没有注册过Vultr账户,现在注册可获得Vultr赠送的免费100美元,有效期30天,另外还可以叠加关注Vultr社交平台获得3美元的促销优惠。
Vultr应该是大家比较熟悉的一个主机商,博主也是从2015年初就开始使用他家的VPS,其特点是按小时计费,可以随删随建,重建自动换IP,也可以选择保留IP,全球16个机房,支持的支付方式有支付宝、信用卡、Paypal、比特币。Vultr在最近两年也是优惠活动频频,从开始的充10美元送20美元,再到充10美元送25美元
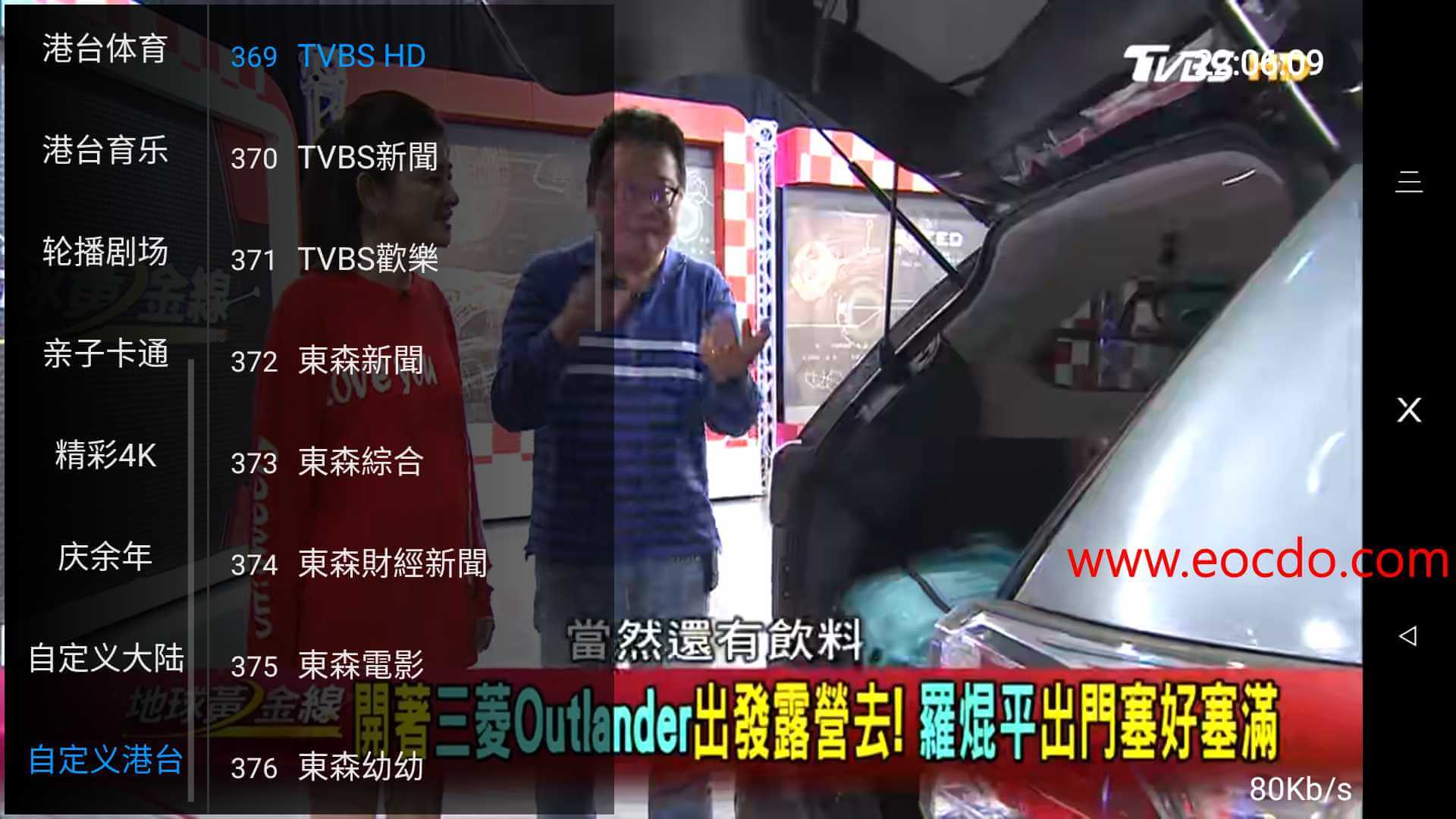
在github上看到一些港台电视节目源,搬运到这里给大家,经博主用HNlive自定义添加测试后,可以流畅播放。关于用HNlive添加自定义电视节目源的教程,请看之前的文章介绍。
在这里给大家分享的主要都是一些纳加vjms格式的源,这组源我在2017年就用过,算是比较稳定的,只是偶尔会出现几天播不了的情况,到目前我知道有三组ip,分别是vjms://58.215.133.185:8500:3502、vjms://23.237.33.155:8500:3502和vjms://121.14.222.75:8500:3502,目前死了的是12
相信很多朋友手里拥有一些各个国家的网盘,比如大家熟悉的OneDrive、GoogleDrive、YandexDrive、Dropbox等,但是一些在大陆的朋友却访问不了这些网盘或者访问速度很慢,于是便想到用一台在大陆能访问的VPS来安装Emby并把网盘挂载为VPS本地硬盘来使用,这样做你既可以访问网盘,还方便管理网盘里面的影视资料,让Emby削刮出精美的海报,建立起你个人高清影视网站,当然也可以使用Emby客户端或在kodi上安装Emby插件来欣赏你的影视大片!
这个教程可能需要花几篇文章来叙述,虽然整个搭建过程可能就只需要20多分钟,但码字和添加图片等文档处理会比较
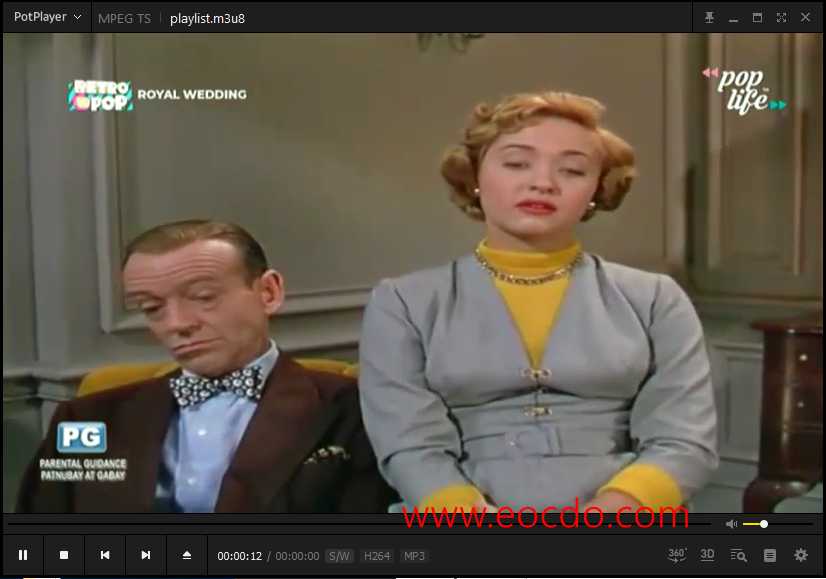
大概半年前抓了一些菲力宾的电视节目源和缅甸电视节目源,昨晚试了下,还能播,发出来给有需要看境外电视的朋友。还有一些一年多前抓的柬埔寨电视节目源,一时找不到,改天再找找给大家。
菲力宾电视节目源:
PacificRack也是一家从2019年黑五以来最热门的商家之一,简称PR,现在又有了新的限量促销,同样是大陆优化CN2 GT线路,年付仅8.88美元,这应该是PR自去年黑五以来最具性价比的一次促销,这个价格已经可以吊打cloudcone,如果正准备购买VPS的朋友,值得入手。
本次促销的机型为KVM虚拟,纯SSD raid10,1Gbps带宽,3Gbps的ddos防御,一个IPv4,主要有以下几种配置:
LIMITED QTY FLASH SALE | 888MB VPS 内存:888M CPU:1核
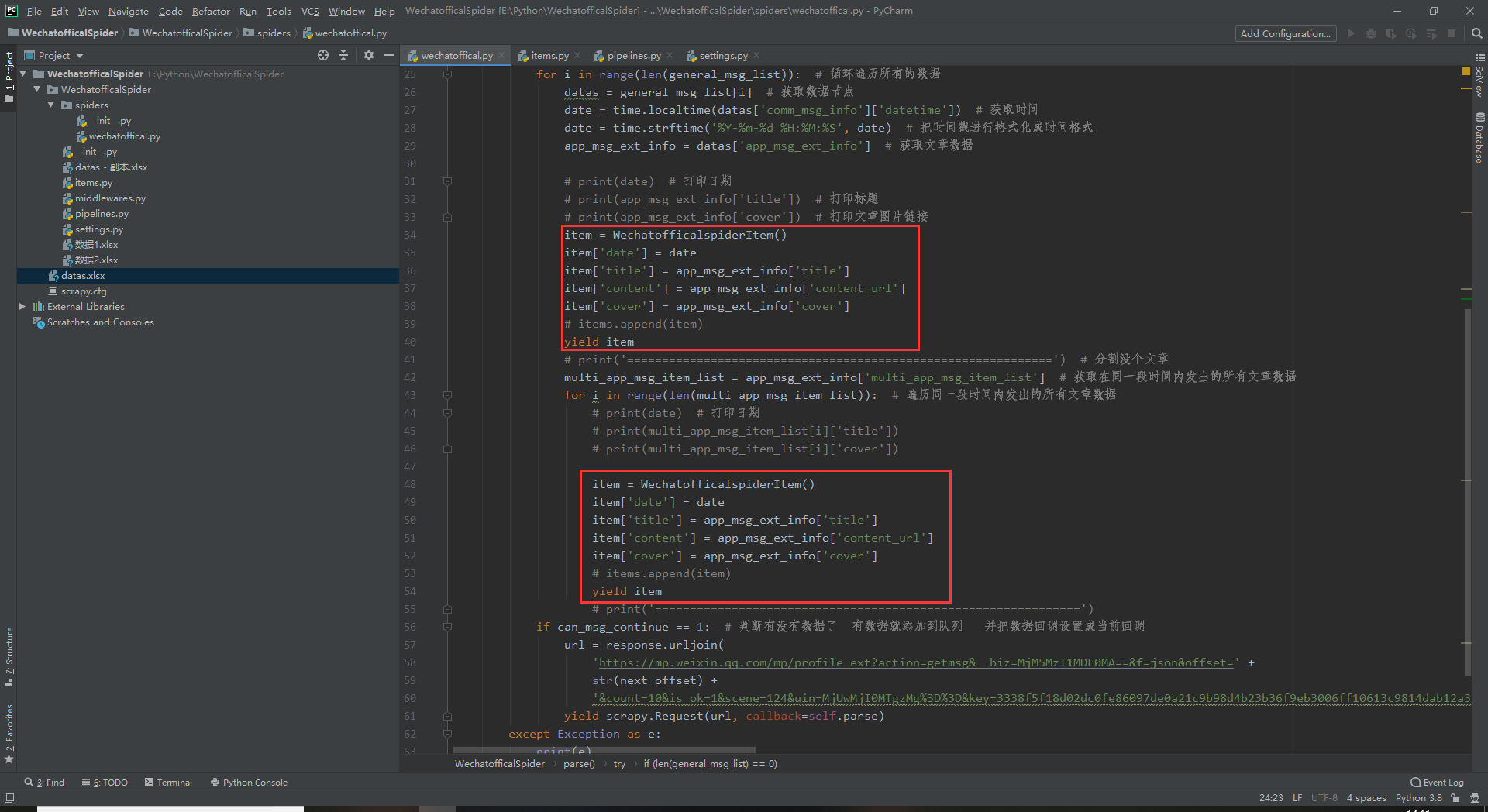
【Python爬虫】Scrapy模块爬取微信公众号历史内容——Python实战篇
前面我们学习了如何抓包、分析、python实战但是唯一的缺点是打印出来的数据分析起来比较困难。今天我们就学习如何导出文件格式为excel的文件可以使用wps officems office进行更可观的数据分析及排序如图所示
开源链接:https://gitee.com/Jamie793/python_scrapy_spider_wechat
【Python爬虫】Scrapy模块爬取微信公众号历史内容——数据分析篇
前两章节中我们学习了如何抓包和分析数据这节我们将开始进行
Python实战打开Pycharm
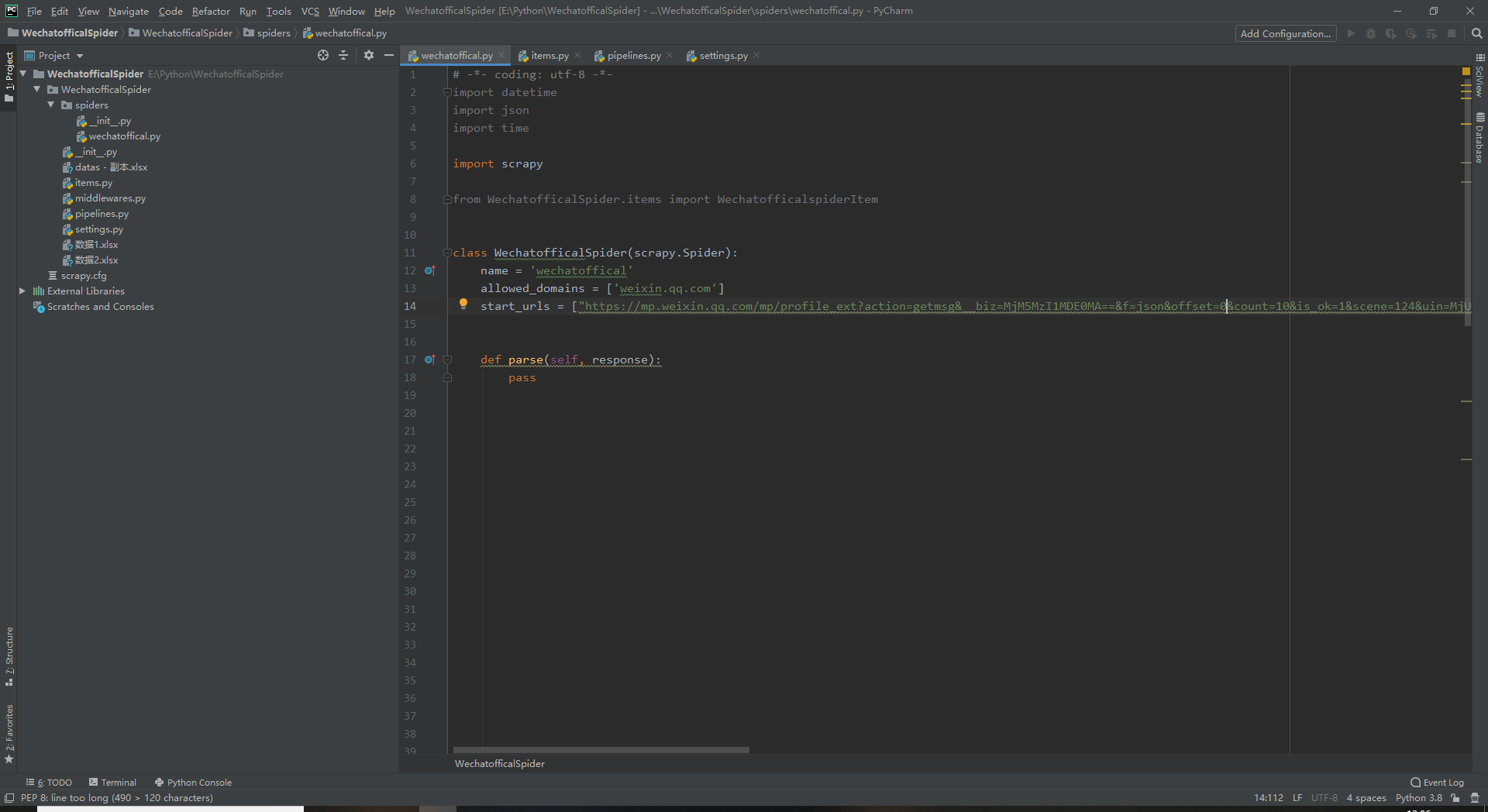
allowed_domains这个呢是只允许爬取在这个域名下的内容,填的是微信公众号的域名都一样的
start_urls这个就是我们前面提取出来的链接把链接的offset改为0就是从第一页开始爬起
parse这个函数是自动生成的
我们需要在这里编写爬虫回调
回调写完后
win+r打开运行输入cmd 输入你文件所在的盘符然后cd到你文件目录
如我是路径是e:pythonspio
先输入e:回车然后
cd pythonspio回车就行了
输入scr
【Python爬虫】Scrapy模块爬取微信公众号历史内容——抓包篇
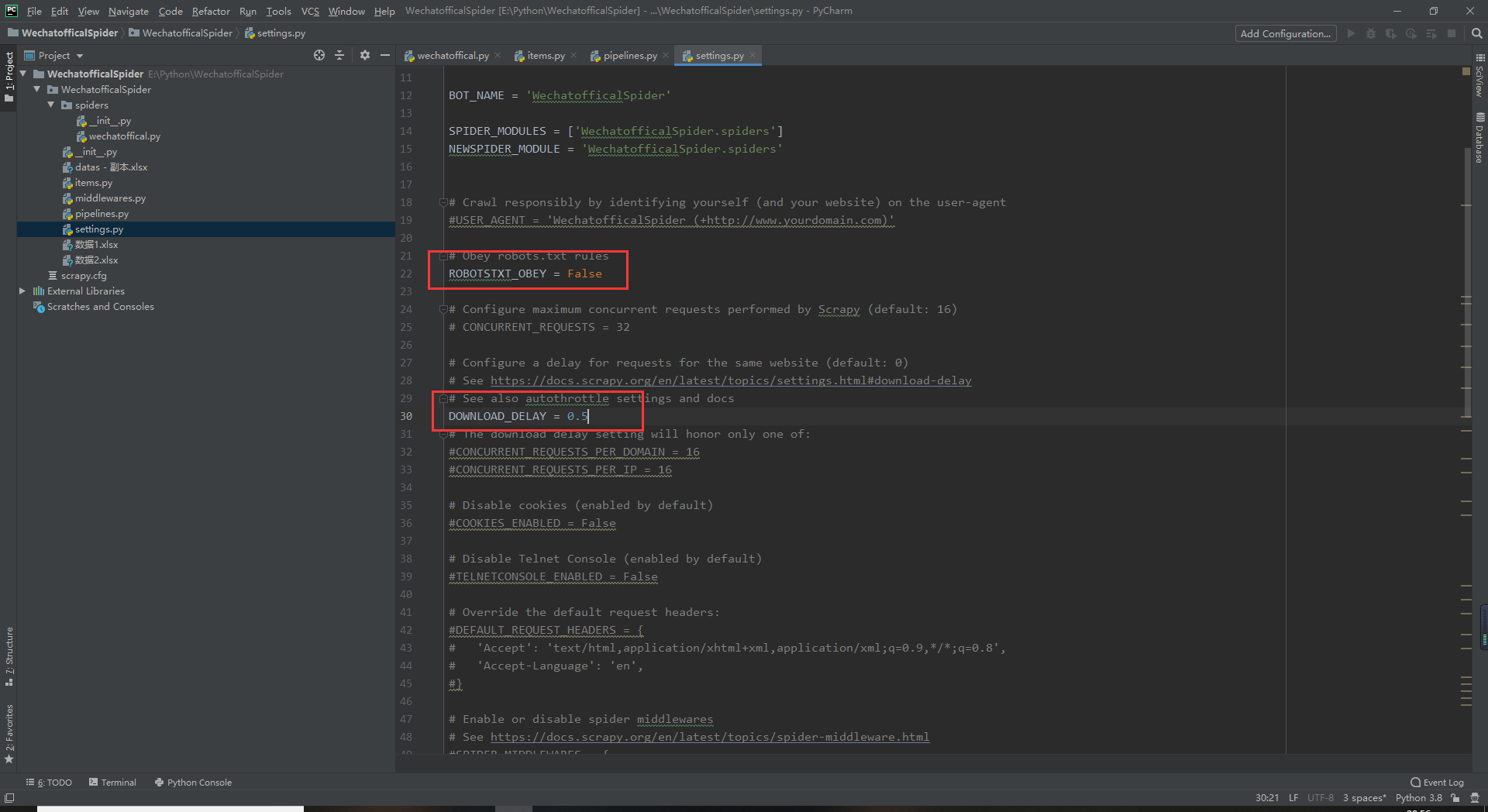
打开后打开setting文件把ROBOTSTXT_OBEY设置成True
DOWNLOAD_DELAY = 0.5 这里是每次发送包后的延迟如图
然后我们对上个文章中获取到的链接进行分析这里我用火狐浏览器因为火狐浏览器自带了格式化json数据的功能
can_msg_continue这个为1就是还有数据为0则没有数据了
msg_count数据的条数
next_offset这个值-1就是得到下一个offset的值
general_msg_list是一个json数据我们需要对他进行格式化这也是我们最需要的