我们首先了解一下 Urllib 库,它是 Python 内置的 HTTP 请求库,也就是说我们不需要额外安装即可使用
发送简单的get请求
python2
import urllib2
response = urllib2.urlopen(‘http://www.baidu.com‘)
pyt
python教程
我们首先了解一下 Urllib 库,它是 Python 内置的 HTTP 请求库,也就是说我们不需要额外安装即可使用
发送简单的get请求
python2
import urllib2
response = urllib2.urlopen(‘http://www.baidu.com‘)
pyt
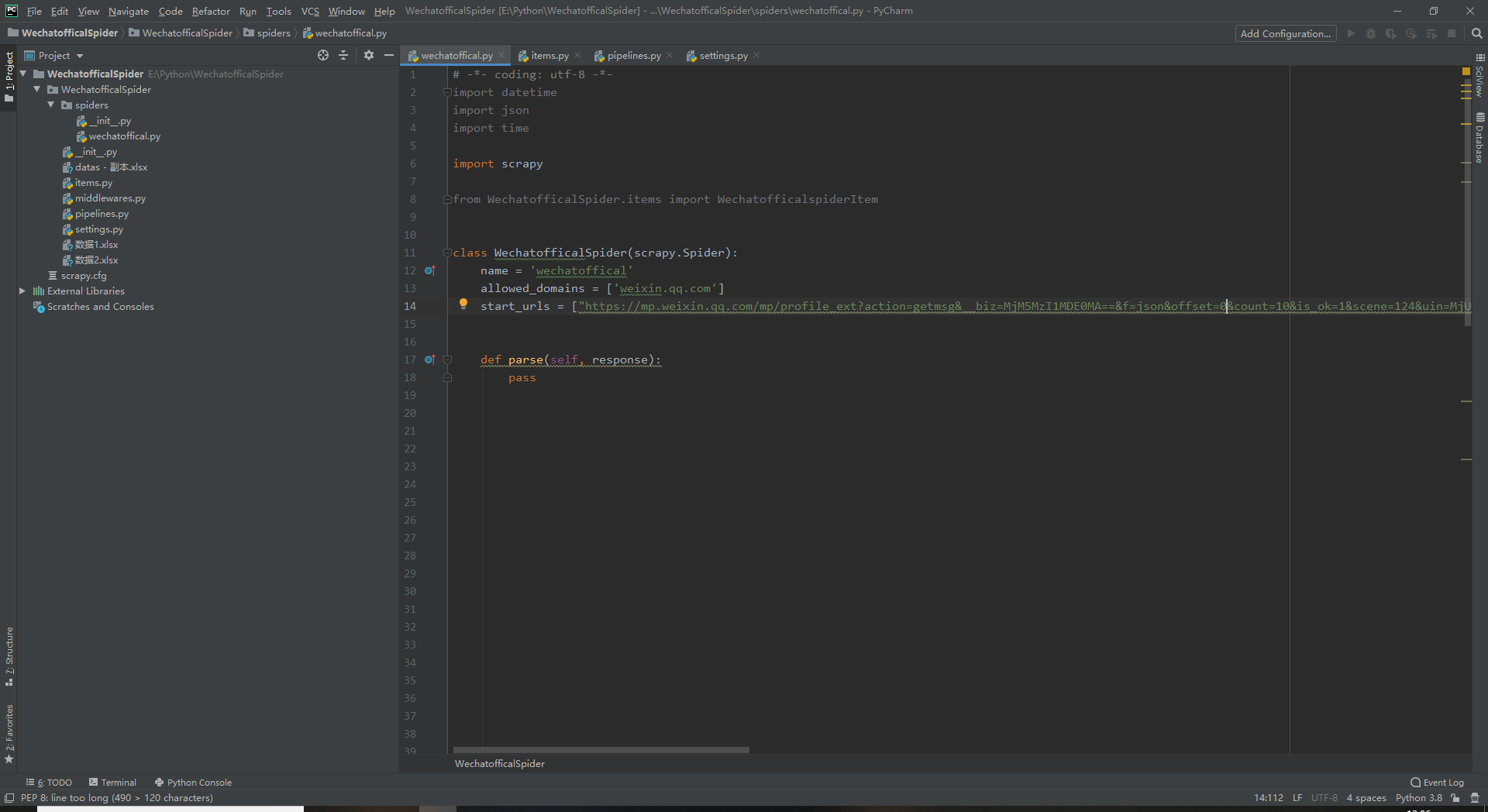
【Python爬虫】Scrapy模块爬取微信公众号历史内容——数据分析篇
前两章节中我们学习了如何抓包和分析数据这节我们将开始进行
Python实战打开Pycharm
allowed_domains这个呢是只允许爬取在这个域名下的内容,填的是微信公众号的域名都一样的
start_urls这个就是我们
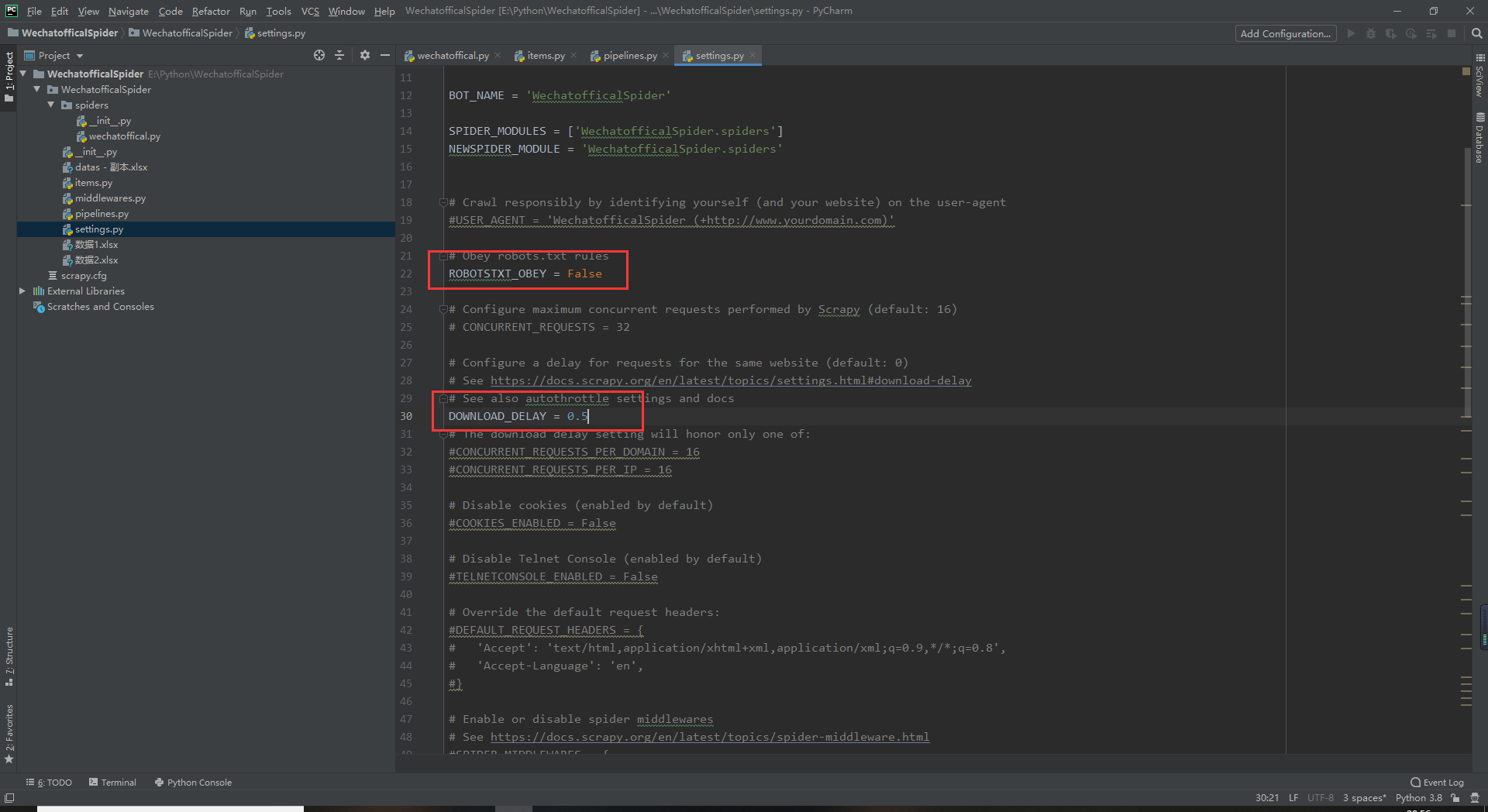
【Python爬虫】Scrapy模块爬取微信公众号历史内容——抓包篇
打开后打开setting文件把ROBOTSTXT_OBEY设置成True
DOWNLOAD_DELAY = 0.5 这里是每次发送包后的延迟如图
然后我们对上个文章中获取到的链接进行分析这里我用火狐浏览器因为火狐